Modernizing Segment's ClickHouse OLAP Platform
Table of Contents
Introduction
Originally posted on: https://segment.com/blog/modernizing-segments-clickhouse-olap-platform
In the world of data analytics, OLAP is often used to describe a technology for processing and analyzing large amounts of data. At Segment, we process and analyze millions of events every second. For over three years, we relied on a relatively simple ClickHouse platform as our primary self-hosted OLAP system. Recently, we decided to modernize our platform to standardize and reduce the operational overhead of our data analytics clusters.
In this blog post, we’ll take a closer look at Segment’s OLAP platform and its evolution toward modernization.
What’s ClickHouse? And how are we using it?
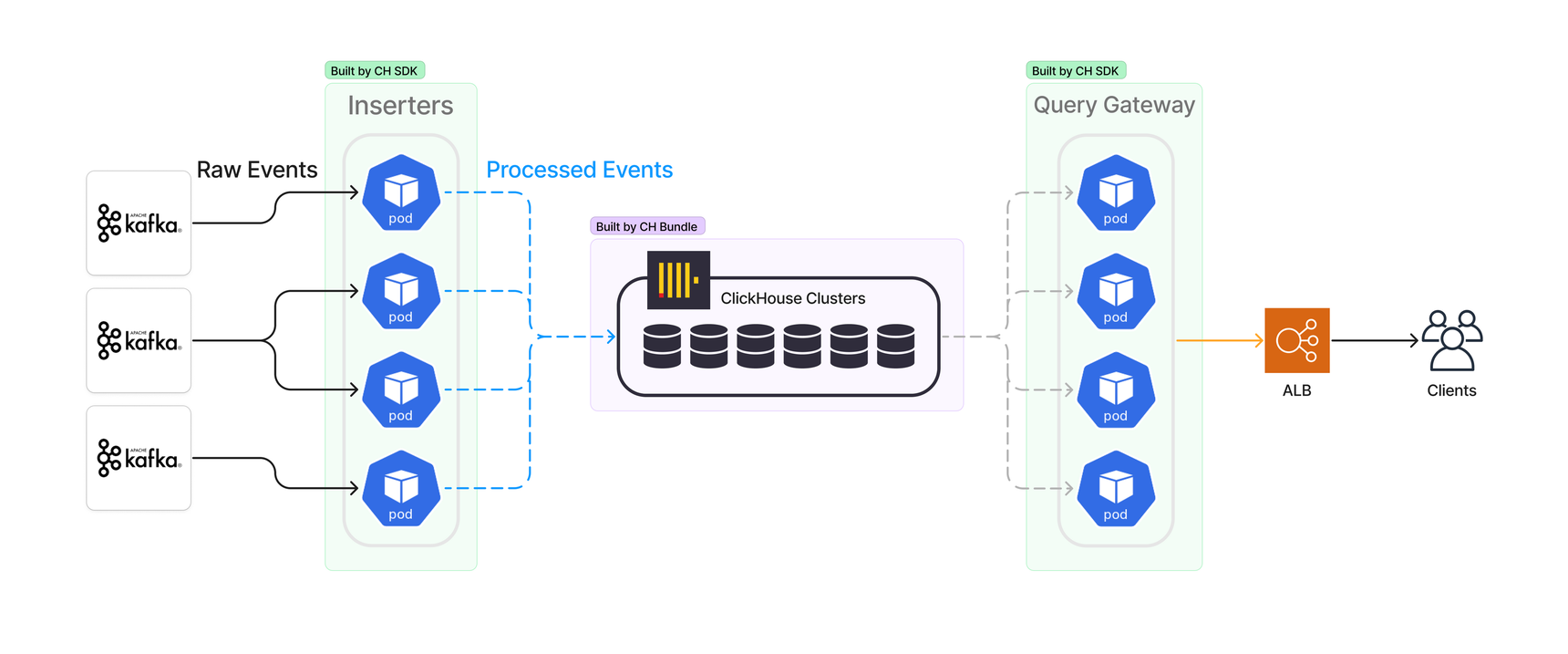
ClickHouse is a column-oriented database that enables its users to generate powerful analytics, using SQL queries. We use it to store and aggregate our processed events in real time. As of writing this post, there are four main components in our ClickHouse OLAP system: Kafka, inserters, ClickHouse clusters, and query gateways.
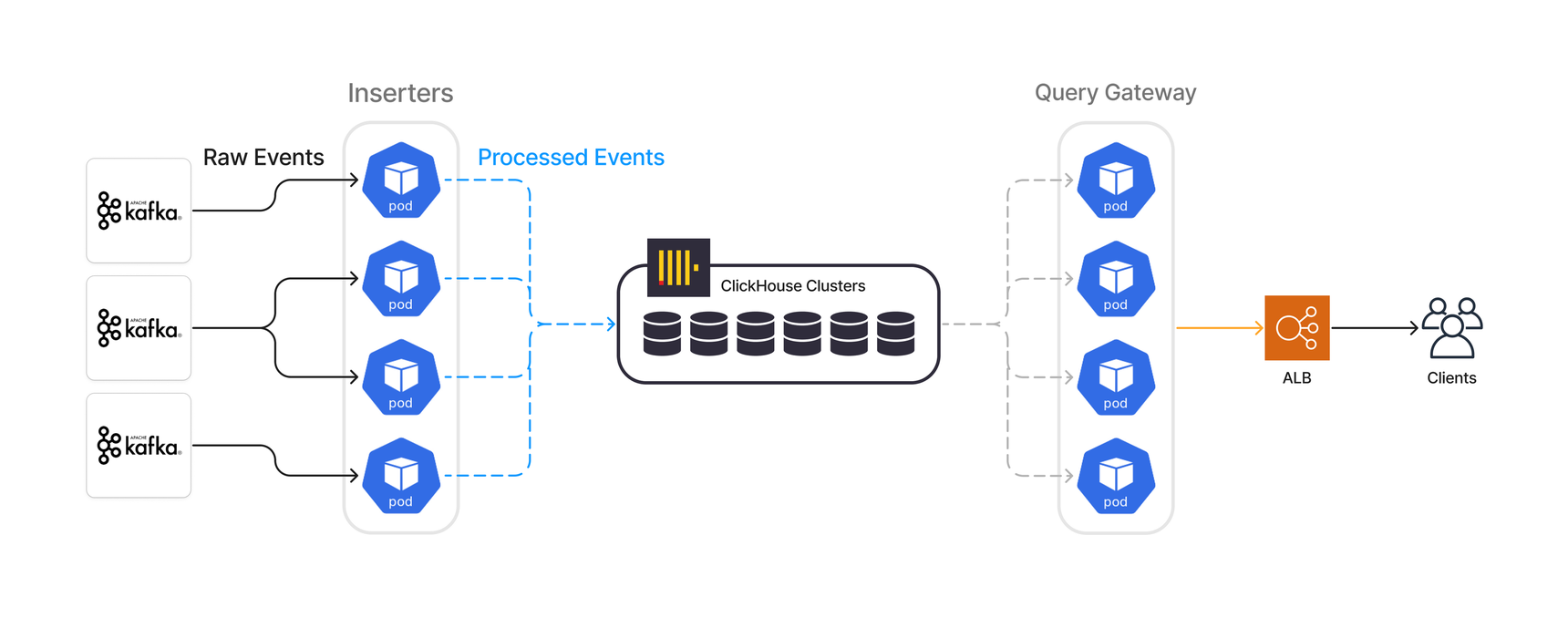
Our inserters consume and process millions of raw events per second and write them in batches into our ClickHouse clusters. The inserters are powered by bespoke Segment libraries written in Go on top of our open-source library Kafka-go. They’re blazing fast and resource-efficient.
In addition, in our legacy platform, we use several in-house technologies around ClickHouse for managing Zookeeper, creating backups, deleting partitions, running data migrations, observability, and monitoring.
Main Problems
Lack of automation
The legacy platform was designed and implemented in 2019. At that time the open-source community around ClickHouse - particularly for Kubernetes - wasn’t as strong as today. As a result, the team had to create numerous in-house projects to keep ClickHouse up and running.
The in-house projects became more and more challenging to maintain as our traffic and the complexity of business logic grew. At this time, ClickHouse also started to receive changes and improvements. Similarly, our routine operational tasks became extensively time-consuming and required a large amount of engineering support. In addition, the other major problem was our operational processes themselves and the reality that most of them lacked automated CI/CD pipelines.
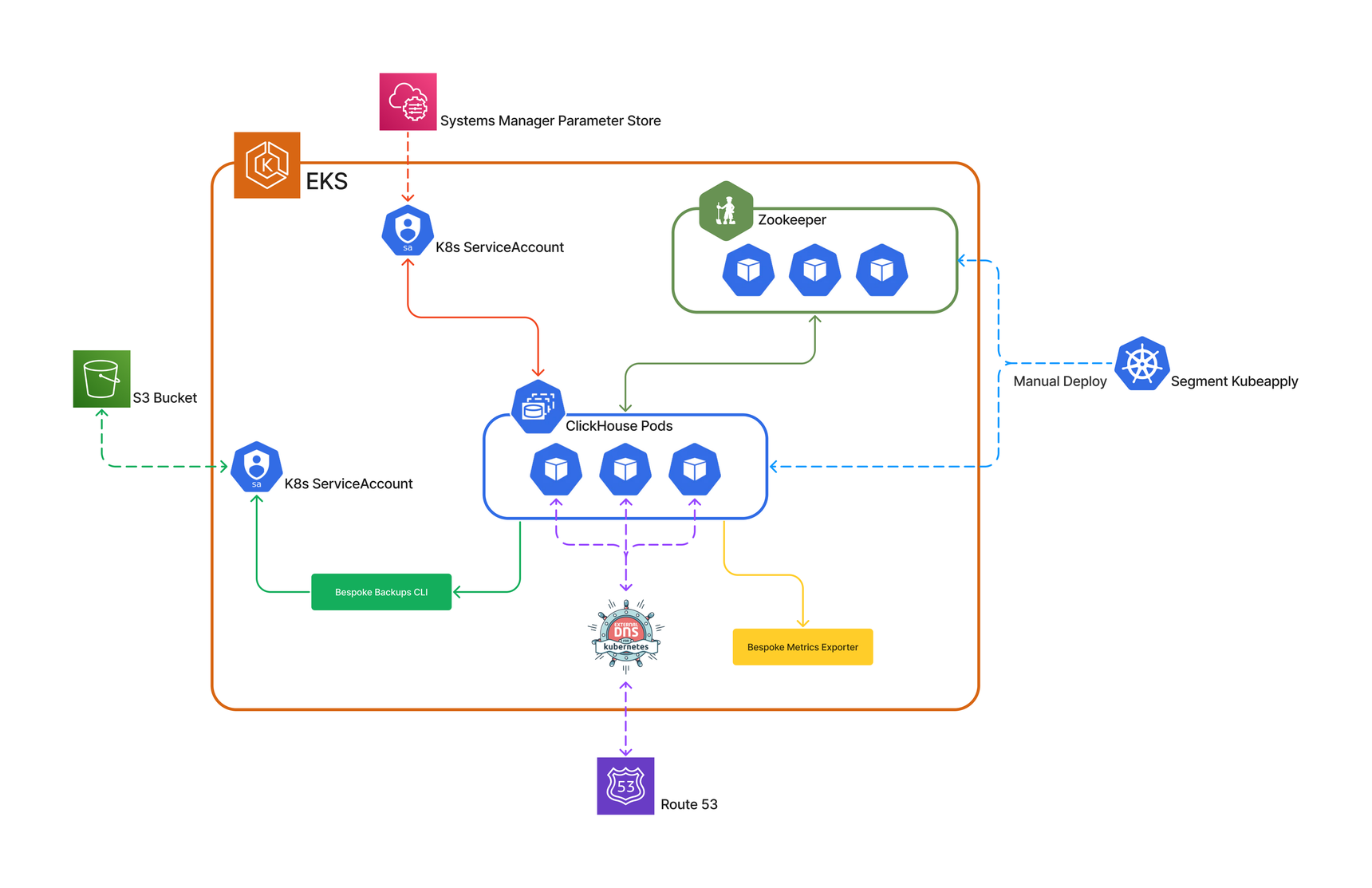
Monolithic clusters
The cost and complexity of maintaining monolithic clusters was the other issue. As mentioned above, since creating a new ClickHouse cluster was a manual process and had a relatively large learning curve, application developers preferred to use the existing clusters for their new product features. This meant that if one product feature needed more resources, we had to scale out the entire cluster based on the pre-defined replication factor. This was not cost-efficient.
Additionally, monolithic clusters had another major challenge for us: data migration. As more teams and product features started utilizing our OLAP systems, our data migration process became less developer friendly and more error-prone.
Introducing the ClickHouse bundle
After months of brainstorming, we came up with a list of requirements to make our OLAP system more developer friendly, easier to use, more resilient, and more cost-efficient. The system:
-
Should be as cloud-native compliant as possible.
-
Should be easy to use so that teams could spin up their own clusters effortlessly.
-
It should provide an SDK and a CLI tool to standardize and simplify the process of building OLAP applications.
-
Should eliminate manual processes, especially for password rotation and data migration processes.
-
Needed to be secure and capable of supporting SSL/TLS encryption.
-
Needed to be resilient and scalable.
We researched Altinity ClickHouse Kubernetes Operator and realized it could help us achieve the majority of our objectives, so we decided to start with the operator and develop all the other necessary features around that.
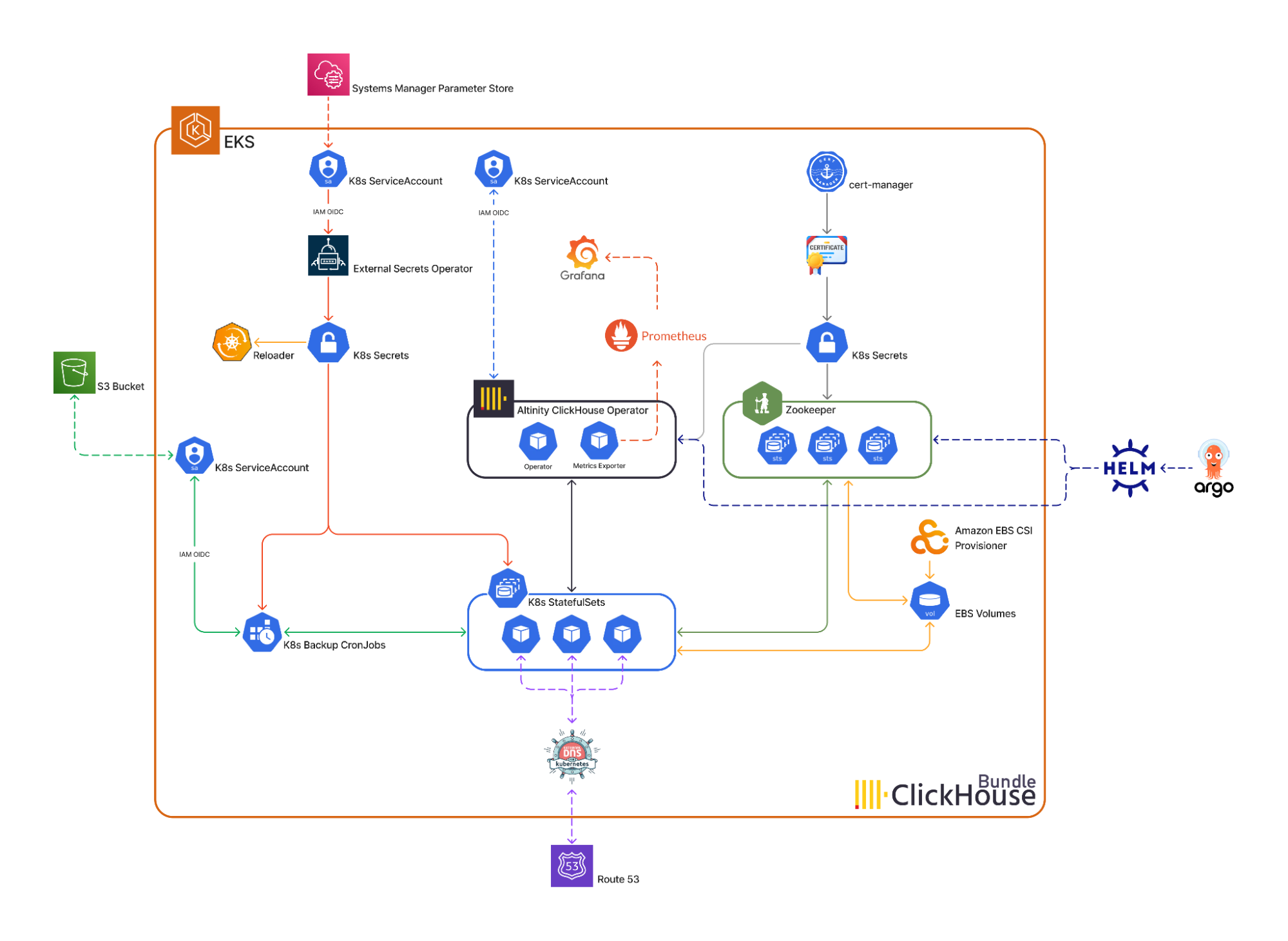
Key features
Let’s examine the built-in features that come with our new ClickHouse platform in more detail.
Automation
In the new platform, Helm and ArgoCD Applications are responsible for managing all of our Kubernetes resources. Thanks to our amazing platform team and our ArgoCD App of Apps design pattern, it’s quite simple to enable ClickHouse Bundle in Kubernetes. All we need to do is to enable ClickHouse as a Helm dependency in the targeted Kubernetes cluster. Everything after that is mostly automated. The Helm dependency will render multiple ClickHouse-related ArgoCD Applications. The operator, Zookeeper, monitoring, and observability tools will eventually be installed by those apps on the targeted Kubernetes cluster.
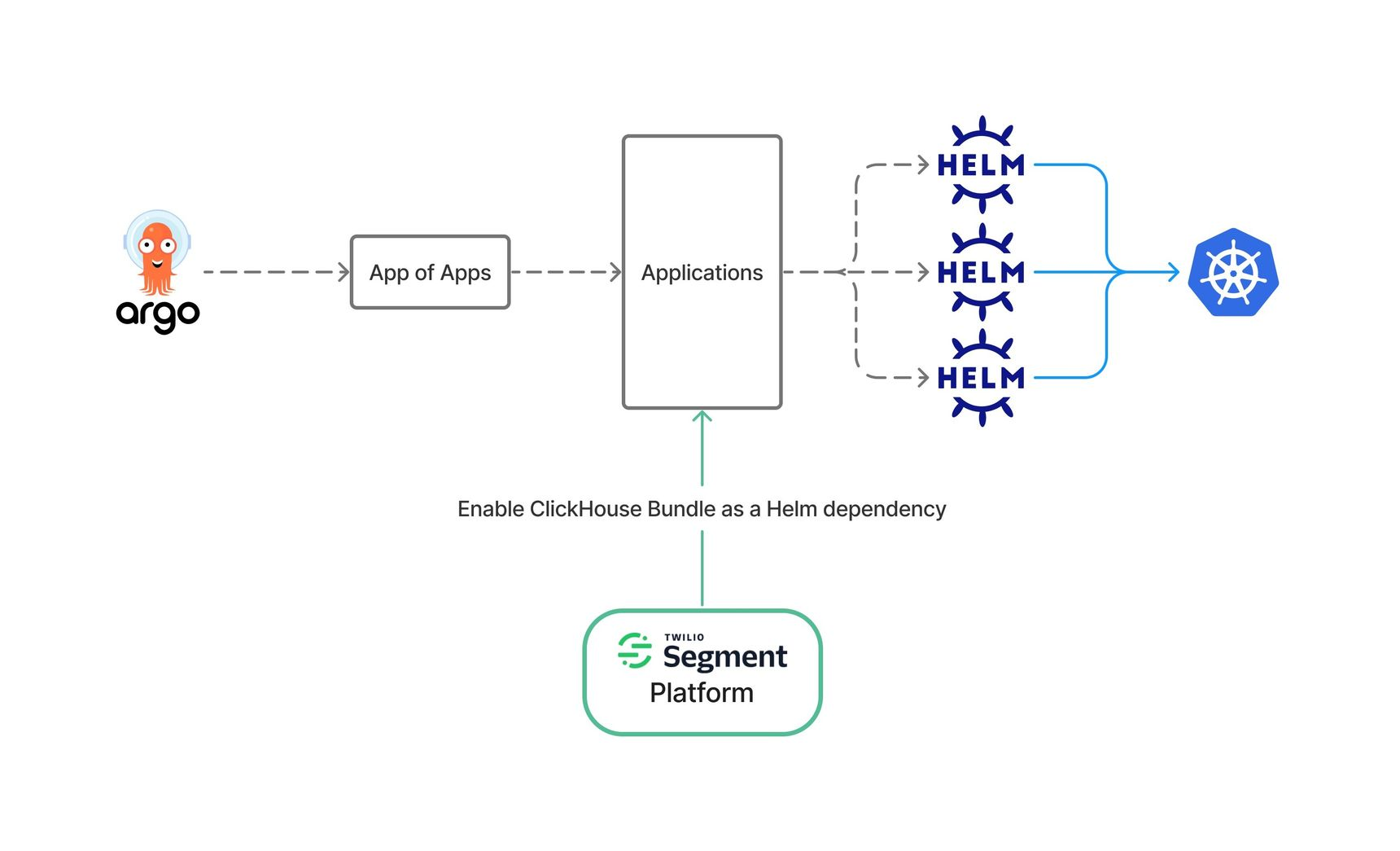
In simple words, we were able to completely automate the processes of setting up and updating ClickHouse and its dependencies by using Helm Charts and ArgoCD Applications. Now our teams can easily create new OLAP clusters in less than an hour by writing a few lines of YAML.
This design also considerably helped us make our data migration process more isolated and less error-prone. After creating and applying a new migration, your primary schema file and its associated configmap will be auto generated. After merging to the main branch, ArgoCD will automatically deploy the new files to the targeted cluster.
Password rotation
Secrets in our new platform are being managed by the Segment Chamber and External Secrets Operator. Chamber is responsible for creating passwords in AWS Systems Manager Parameter Store or AWS Secrets Manager and External Secrets Operator is responsible for bringing them safely into our Kubernetes clusters. Reloader is also responsible for restarting the running pods to ensure they have the latest secrets. The beauty of this design is once we rotate our passwords via Chamber, the newly updated password will automatically get propagated through our system which makes our password rotation process incredibly simple.
SSL/TLS Certificate Management
In the ClickHouse universe, multiple types of connections could be secured by TLS (e.g. server-to-zookeeper, server-to-server, client-to-server connections, etc.) To secure all of these connections, SSL/TLS certificates are required. An SSL/TLS certificate is a digital object that allows systems to verify the identity & subsequently establish an encrypted network connection to another system using the Secure Sockets Layer/Transport Layer Security (SSL/TLS) protocol. This part has also been drastically simplified thanks to cert-manager. Cert-manager adds certificates and certificate issuers as resource types in Kubernetes clusters and simplifies the process of obtaining, renewing, and using those certificates.
CSI Driver
The Container Storage Interface (CSI) specification defines APIs to add and configure storage provisioners in Kubernetes clusters. These APIs enable the discovery of storage capabilities and define new Kubernetes resources to manage advanced storage features.
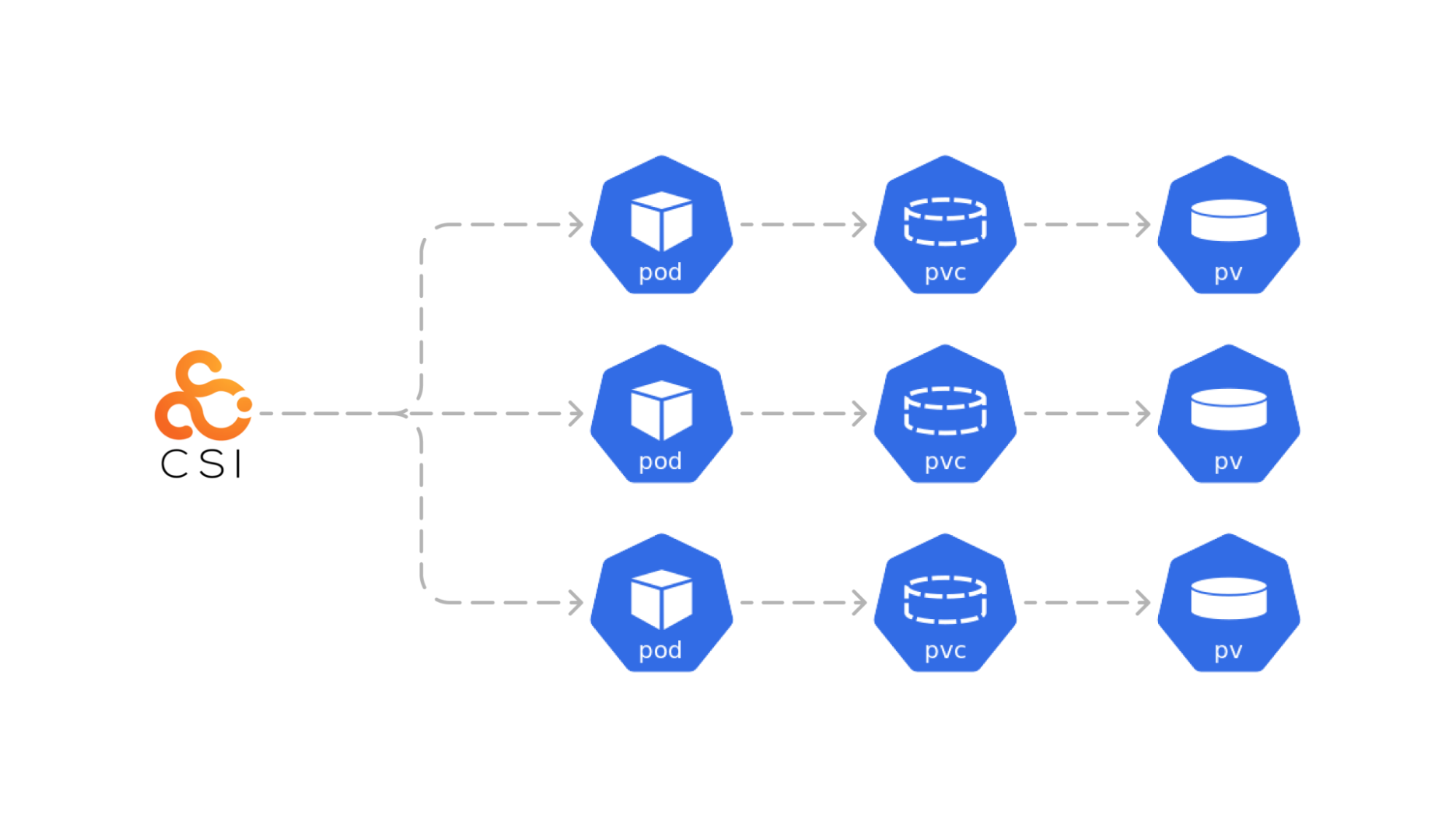
Since our Kubernetes clusters are primarily on AWS EKS we use aws-ebs-csi-driver to manage the lifecycle of Amazon EBS volumes for Zookeeper and ClickHouse. This feature is completely optional since EBS volumes could be cost-prohibitive for some use cases.
Tiered and hybrid storage
For quite some time, ClickHouse was lacking this storage option, which made many companies choose Druid over ClickHouse (pets vs. cattle). ClickHouse, unlike Druid, doesn’t need deep storage. As a result, each ClickHouse node plays a critical role in your cluster and losing a node could potentially cause data loss. However, when a node fails on Druid, the cluster continues to operate and no data is lost. All data always exists in deep storage.
Over the past few years, the ClickHouse open-source community has been actively working on this concern and now ClickHouse can use S3-compatible storage. For our use case, we were particularly interested in tiered storage.
Tiered storage is a storage architecture that involves organizing data into different tiers or levels (hot, warm, and cold) based on value, access frequency, and granularity. This architecture has several benefits including cost optimization, performance improvement, enhanced data protection, scalability, and better resource utilization. For example, we can store our recent data in SSD (instance storage), our warm data in HDD (EBS volumes), and our historical cold data in object storage (S3). This capability is templated and integrated into our platform, making creating tiered storage a breeze.
Conclusion
To sum up, we went through the evolution of our ClickHouse OLAP platform from being a simple monolith system on Kubernetes to an orchestrated and automated platform managed by Helm and ArgoCD. In particular, we went through the details of how to automate time-consuming manual processes like installing dependencies, data migration, and password rotations.
We briefly discussed decoupling, in the sense that it’s easier in our new platform to isolate specific clusters and grow them individually. We also talked about storage and compute separation in ClickHouse through S3-compatible storage. This covered the core architecture of our platform and its essential components.